
I’ve written a few posts on Sitecore Content Search and Solr already, but there seems to be an infinite amount of things to discover and learn in this area. Previously I’ve pointed out the importance of configuring the Solr index correctly and the benefit of picking the fields to index, i.e. not indexing all fields as default (<indexAllFields>false</indexAllFields>). This will vastly improve the performance of Content Search operations and reduce the index size in large solutions.
Recently I’ve been investigating a performance issue with one of our Sitecore solutions. This one is running Sitecore 9 with quite a lot of data in it. It’s been performing quite well, but as the client were loading more data into it, it got a lot slower. Our metrics also showed the response time (P95) in the data center that got quite high. It measured around 500 ms instead of the normal 100 ms.
The cause of this wasn’t obvious and most things looked good. Database queries were fast, caches worked as expected, CPU load was somewhat high, but not overloaded. I also looked at our Solr queries and the query time reported by Solr were typically below 25 ms. It wasn’t until I looked at network traffic between the servers, I discovered that a lot of data were sent between Solr and IIS. IIS received about ten times the data as it was sending/receiving to/from any other system.
So I started looking at the actual queries being performed and I knew some queries returns many records. But I was surprised when I found queries returning payloads of 500kB or more. This creates latency and CPU load when parsing it!
So I started digging into our code and at first glance everything looked quite good. The code followed a regular pattern, like:
public class MyModel {
[IndexField("_group")]
[TypeConverter(typeof(IndexFieldIDValueConverter))]
public ID ItemId { get; set; }
[IndexField("_language")]
public string LanguageName { get; set; }
// more needed fields ....
}
var result = searchContext.GetQueryable<MyModel>()
.Filter(filters)
.GetResults();
foreach (var myModel in result.Hits) {
// do stuff
}
I soon realized that Sitecore puts fl=*,score (Field List) in the Solr query string. You can see this in your Search.log. This means all stored fields are returned in the result. But in most cases we were only interesting in one or a few fields, like the ones specified in our model MyModel. So I looked at finding a way to fetch only the required fields. writing the queries in a way where only the needed fields were returned. It turned out that the LinqToSolrIndex were indeed managing a field set and builds the Solr fl parameter out of that.
So it turns out we can use the Select feature before GetResults to control the fields list. However, it complicates the code a bit, because it means that MyModel in the example above won’t be returned, but it is used when picking the fields and for constructing the query. The code pattern below explains it a bit more. Note: You don’t have to use different models and the query model doesn’t have to inherit the result model. I’ve written it like this to clarify the relation. It’ll probably become easier to understand when writing this in Visual Studio and you see what Intellisense gives you.
public class MyResultModel {
[IndexField("_group")]
[TypeConverter(typeof(IndexFieldIDValueConverter))]
public ID ItemId { get; set; }
// more fields requested
}
public class MyQueryModel : MyResultModel {
[IndexField("_language")]
public string LanguageName { get; set; }
// more fields needed for filtering....
}
var result = searchContext.GetQueryable<MyQueryModel>()
.Filter(filters)
.Select(x => new { x.ItemId, /* more fields requested */ })
.GetResults()
.Select(x => new MyResultModel {
ItemId = x.Document.ItemId,
/* mapping of more requested fields */
});
foreach (var myResultModel in result) {
// do stuff
}
Essentially, you can use Select to control what fields are returned, but you’ll also get a dynamic type returned that you probably want to convert back into a typed model.
So, was it worth doing those code changes in the project. Well, the answer was YES! I went through all Content Search queries that could return more than ten rows, i.e. queries that didn’t have a low .Take(n) value.
As I mentioned previously, we had already optimized the index storage, so we were already storing only the field we’re actually using in the application. Still I found that every record was quite heavy. In the serialized XML used in the network transport between Solr and Sitecore, every record were around 3630 bytes. When picking only the fields needed, we got down to around 270 bytes each. The performance within the data center improved a lot. The response time figure looked like this before/after deploying this code change:
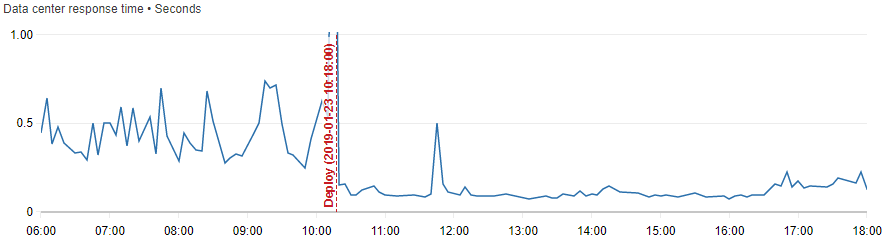
I was blown away how much difference this did to the solution as a whole. And the Solr queries are still not perfect. Looking at the search log, there are still a few additional fields returned from Solr that I don’t need. It turnes out that Sitecore adds the fields _uniqueid, _datasource and score regardless of what I select. So my 270 bytes/record could go as low as 70 bytes/record if those were removed too, but that would probably be sub optimizing…
I don’t know why Sitecore always adds the first two, and the last one, score, turned out to be a bug. The GetResults method has an optional GetResultsOptions enum parameter. It may be Default or GetScores. However this parameter doesn’t do anything. Sitecore will always ask for score, unless you do something like ToArray instead of GetResults. That could be an option to reduce it a bit more, but then you won’t get the TotalSearchResults or Facets properties.
So my recommendation is to look through your Search.log and filter out the rows where fl=*,score and rows=a large number. Consider optimizing those with a limited field list or number of returned rows.
Hello Mikael,
Thanks for detailed explanation. It’s really very helpful post. We’ve improved the solr search query performance using the same approach you’ve mentioned.
As you’ve mentioned, Sitecore adds the fields _uniqueid, _datasource and score regardless of what I select and it’s a bug. Can you please share the support ticket id, so that I can be updated? (we are using Sitecore 9.0 update-2).
Thank you,
Thank you for the feedback! The _uniqueid and _datasource are always added, and I have not reported that one. The _score is always added as the GetResultsOptions enum is ignored. This is reported and put on the backlog for future releases. I have not requested a patch for that, as it doesn’t break the product. It’s just a small feature that isn’t implemented.
I believ e_uniqueId is required if you want to do a `.GetItem()` using the out-of-the-box Sitecore SearchResultItem class. It uses the _uniqueId to get the *exact* item based on language, version, id and database. I’ve run into issues with this before where an old item is in the index and you call `.GetItem()` which then returns null because the item no longer exists in the database (unpublished, for example) even though you know the item still actually exists. On closer inspection, I realized it wasn’t just getting whichever version existed in the current context language for the ID, it was trying to get the *exact* version specified in the _uniqueId field in the index.
Yes, that’s true. The _uniqueid is parsed as a ItemUri containing everything that’s needed to do the GetItem. It essentially just gets the database followed by a GetItem with ID, Language and Version.