
Sitecore has been using the unversioned standard field “__Display name” along with the built-in “Name” for as long as I can remember. Basically, the item Name is similar to a shared field and is limited to small set of characters. An item name can basically be A-Z, a-z, 9-0, space and a few special characters, such as underscore (_), dash (-), dollar-sign ($). It may also be a single star (*).
Since the Name is very limited, the __Display name fields allows users give item more user friendly names. Since it’s persisted in an unversioned field, it also allows for translation. The Sitecore.Data.Items.Item class has a convenience read-only DisplayName property that returns the content of the __Display name field, if set, otherwise it fallbacks on the item Name. This principle is used basically everywhere in Sitecore. It’s used when rendering the item tree, as link text on rendered links and so on.
In Sitecore 9.2 (I believe), Sitecore made a small, but very important breaking change on how the Display Name works. I can’t recall seeing this change been noted in any release notes either, but I might have missed it.
Update: I realize I’ll need to keep updating to this post as I receive more input. I’ll keep them the bottom of the post.
How it works from Sitecore 9.2
Sitecore is following the common best practice of storing content close to its native format. I.e. texts are stored as plain text in the database etc. Content is then encoded at render time, matching the output format. So if you render a text field on a page it becomes html encoded, if you pass it on to a Url, you URI encode it and so on.
However, this is no longer the case for the “__Display name” field. Sitecore is now persisting this field, and only this field, in a html encoded-ish format. Sitecore have decided to store the following characters encoded according to the following table:
| Character | Encoding |
< | < |
> | > |
& | & |
" | " |
' | ' |
( | ( |
) | ) |
# | # |
Note how a mixture of html named entities, numeric entities and hex entities are used and the common & isn’t used. Also note that parenthesis are encoded, that’s usually don’t need encoding.
How this affects our solutions
This causes some headaches to us developers since we have to deal with double encoding and we have to decode this field before passing it on to any non-html output format. Here is a code example of a .cshtml Razor view of why this becomes a problem:
<!-- This will render just fine -->
<div>@Sitecore.Context.Item["MyField"]</div>
<!-- These won't render correctly, as it will be double encoded -->
<div>@Sitecore.Context.Item.DisplayName</div>
<div>@Sitecore.Context.Item[Sitecore.FieldIDs.DisplayName]</div>
<!-- This will however render correct -->
<div>@Html.Raw(Sitecore.Context.Item.DisplayName)</div>
And this obviously applies to all outputs where this is used, so if we want to put this in a JSON, like in a REST API, we’ll have to perform a HttpUtility.HtmlDecode(Sitecore.Context.Item.DisplayName) before passing it on to the target model and so on.
To make things even more complex, Sitecore has chosen to implement this in the Sitecore.Pipelines.Save processor in the <saveUI> pipeline. The processor now contains the method NeedsHtmlTagEncode, that returns true for, and only for, the __Display name field. When this hits, the processor performs the following change the content of the field:
field.Value = WebUtil.SafeEncode(HttpUtility.HtmlDecode(field.Value));
So, basically decoding and encoding again. As the “saveUI” pipeline name implies, this pipeline runs when an author saves an item through the Sitecore UI. It doesn’t run when we add/modify items from code. So any code we have, that plays with this field, such as save actions, integration code, 3rd party modules, Sitecore PowerShell (SPE) scripts and so in, needs to be updated. Below are some examples to illustrate this:
/* C# example */
myItem.Editing.BeginEdit();
// This works just as before:
myItem["myField"] = myNewValue;
// But this is now wrong:
myItem[FieldIDs.DisplayName] = myNewDisplayName;
// It must be written like this:
myItem[FieldIDs.DisplayName] = WebUtil.SafeEncode(HttpUtility.HtmlDecode(myNewDisplayName));
myItem.Editing.EndEdit()
// And this is still wrong:
myItem["myField"] = WebUtil.SafeEncode(HttpUtility.HtmlDecode(myNewValue));
# Sitecore PowerShell Extensions example
$item = Get-Item .
$item.Editing.BeginEdit()
# This is now wrong
$item['__Display name'] = $newDisplayName
# Must be written like this
$item['__Display name'] = WebUtil.SafeEncode(HttpUtility.HtmlDecode($newDisplayName));
$item.Editing.BeginEdit()
By now, you’ve probably realized how easy it is to make those mistakes. If you’re working on a Sitecore 9.2, 9.3 or 10.0 solution, I bet you’ve missed this in a few places. But don’t despair. Sitecore couldn’t get it right either.
Current implementation errors
When this change was introduced, so was a bunch of new bugs as well. When writing this, all releases of Sitecore (9.2, 9.3 and 10.0 update-1) contains bugs that are directly related to this. Some were fixed in later versions and some have been fixed with cumulative updates:
On some versions, editing the __Display name field in the Content Editor (when showing Standard fields), will double encode the content. So if you have named an item “Q & A”, it’s persisted as Q & A. Modifying the field and save it again will persist Q &#38; A, i.e. it becomes double encoded over and over again on every save that touches the field.
Editing the Display Name through the dialog box in the Content Editor, via the Home ribbon, will just encode the first entity. So if you give it the name “A & B & C”, it’ll be persisted as A & B & C. I’ve also seen this dialog result in the more common & entity instead. So obviously there are multiple implementations of this encoding in the platform.
If you enable the <useDisplayName> option in the urlBuilder, the LinkManager will cut off the URL on some versions. So if you have a “Questions&Answers” page, you’d expect the URL to become “questions,-a-,answers“. This is because the “&” character is replaced with “,-a-,” according to encodeNameReplacements configuration. However, the LinkManager may cut the URL after the first entity, resulting in just “questions,-a-,“, hence it also becomes unresolvable resulting in a 404 when accessed.
Why was this change made?
I don’t know why this change was done in the first place, so this is purely speculations from my side. Many parts of the Sitecore UI is built long ago using the classic ASP.NET Web Forms (.aspx/.ascx files). Those didn’t automatically encode the output, as Razor does, so my guess is that Sitecore found that encoding was missing in many places. They probably thought encoding it in the database instead would be an easier fix. You can try this yourself, by setting the __Display name field to something like “Home<script>alert('Hi');</script>“. (Obviously through code – not through the saveUI pipeline that encodes it). Notice how those dialogs pops up everywhere…
However, if this was the reason, I don’t think it justifies such breaking change. It wouldn’t be too time consuming, finding all places where encoding is missing, if one just pops dialogs like in the example above. Pushing the problem to us implementing partner just isn’t right.
What should be done?
Just to be clear, I’m not against breaking changes. It comes with an evolving product. But I don’t like when changes comes like this. No clear release notes, no deprecated API’s, all code compiles as if nothing was changed and so on. If this kind of change is really needed, I’m totally fine with performing API changes, such as having the FieldIDs.DisplayName property marked as [Obsolete], the Item.DisplayName returning IHtmlString and so on. Then we would at least get some kind of heads-up before running into trouble.
In this case, I think Sitecore should spend some time reverting this change. Yes, there are three released versions containing this change, but none of them handles it correct. They all all needs patching anyway. There is still a small window left to correct this slip ones and for all before it becomes an irreversible change.
Please share your thoughts on this.
Background / History / Updates
I’ve written this post as per request from the community Sitecore Slack #architecture channel. I wrote a shorter version of the above on February 1st, 2021. It got some thumbs up and face-palms reactions as well as some good comments. A few quotes below:
“why WOULDN’T you start inconsistently html-encoding content to be stored in a database?”
“Perhaps some client put it in as a support request that fit their requirements and it got merged in by mistake”
“… Up through the 9s, the kernel has been maintained in the same way an inhouse development team would trim their project. Not like a platform at all. … I’ll bet you there are more breaking changes between 9.1 and 9.3, than between 6.6 and 8.2”
“… you spotted an important issue. I am carefully reviewing all release notes but cannot remember this change ever mentioned. For me it looks like a silent breaking change into backward compatibility, that should not take place in that way. … I don’t think it should be reverted once got there, and [t]he longer it is there – less chance to get it reverted. … you should copy your message into a blog post and we can all share across the community. From my side, I will be soon talking to the team responsible for Kernel and will definitely raise that with them. What would be helpful is having all these thought somewhere (your blog) with an URL I could share.”
Upate February 3rd
As Rasmus pointed out on Twitter, we could see Display Name as internal and used only by Sitecore. I think that could be a good way moving forward. However, that also means that Sitecore should stop using Display Name as default text when rendering links. It would make sense to introduce a versioned link text field for this purpose.
As Jonas pointed out on Slack, the encoding method, in prompt.js used by the Display name dialog, is also used when editing values in the rules editor. This causes double encoding in the Rules engine. His screenshot shows it clearly:
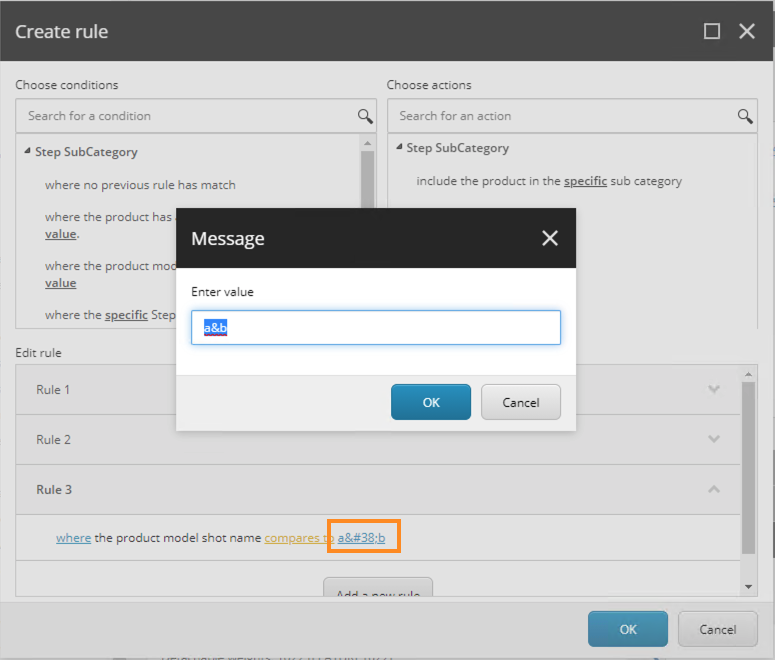
Jonas also pointed out that item.Appearance.DisplayName set property also uses a different way of encoding the content, where just < and > is encoded as < and >. All other characters, including &, is left as-is. The conclusion “… this feels like a slippery slope of never-ending problems. … How does this affect things like solr searches, powershell reports etc.?” is very relevant.