
While investigating stability issues, I’ve found a few things that may need addressing.
Sitecore updates indexes in batches. This is good in general, but it turned out it may be very memory hungry. There are essentially two config parameters you can control the batch size with:
<setting name="ContentSearch.ParallelIndexing.Enabled" value="true" />
<setting name="ContentSearch.IndexUpdate.BatchSize" value="300" />
The default config above, essentially means Sitecore will start multiple threads processing 300 indexable objects each. This might not be an issue at all, but when combined with a multi-language setup, media indexing and crazy authors, this may become a real problem.
Let’s say you have 30+ languages in a solution. When uploading a media item, Sitecore creates a version on every language. (Yes, you can disable this, but you need a version on each language in order to have localized meta data, such as alt-texts on images etc.) When Sitecore indexes this, all these 30+ versions will be loaded as individual “Indexable” items into the indexing batch. On a media item, such as a PDF, the binary data will be extracted and placed into a BatchUpdateContext queue that’ll be sent to Solr (or whatever search provider you use). While in the batch, they are all loaded into RAM as individual copies waiting to be handled by Solr.
I found a document uploaded by an author that became over 20 million characters when extracted into the _content computed field. Given that each char is two bytes, this 40MB string times the number of language versions occupied almost 1GB of RAM while being in the indexing queue.
We did have a lot of indexing issues, but I found this by accident while analyzing a memory dump. I looked at what media items where in the database and found that if I’m unlucky, two threads with 300 indexables can easily consume all my 32GB RAM and crash the process…
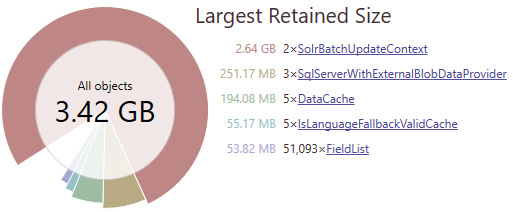
Quick solution to this was to just reduce the BatchSize, so that fewer large objects would go into SolrBatchUpdateContext.
Long term solution is to replace the entire _content computed fields with something more optimized. I rarely find any good use of this field anyway, since it doesn’t perform proper language stemming anyway. Nor does it make sense to load the shared binary data over and over again for each language when indexing it. Extracting useful content into a separate shared, hidden, text field at upload is much more efficient.
Pingback: Sitecore Memory Issues – Every memory optimization trick in the book | Brian Pedersen's Sitecore and .NET Blog