
I discovered that the heap gets very fragmented in SQL Server in some of our solutions. Large tables, such as Items, Shared-, Versioned- and Unversioned-fields, Blobs, Descendants and Links tables, that easily occupies a few GB on disk, also suffered from great fragmentation. More than 90% fragmentation was common.
From what I’ve found, the only way to fix SQL Server Heap fragmentation (the heap is where all the table data is stored), is to have a clustered index on each table.
However, I noticed that no tables in the Sitecore databases have any clustered indexes. All indexes are non-clustered in the common master/core/web databases. Sitecore used to have clustered indexes back in 5.2, but over the course of multiple Sitecore versions, the database schema has changed to non-clustered indexes.
A clustered index means that the table rows as stored in the index order physically on disk. That’s also why there can be only one clustered index per table. With a non-clustered index, there is a second list that has pointers to the physical rows. It’s generally faster to read from a clustered index, but it may be slower to write to it as there may be a need to rearrange the table data.
You can find the fragmentation for all indexes and the table heap with the query below. Returning rows where the Index column is NULL, shows the fragmentation of the heap, i.e. the table data in this case.
SELECT dbschemas.[name] as 'Schema',
dbtables.[name] as 'Table',
dbindexes.[name] as 'Index',
indexstats.alloc_unit_type_desc,
indexstats.avg_fragmentation_in_percent,
indexstats.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), NULL, NULL, NULL, NULL) AS indexstats
INNER JOIN sys.tables dbtables on dbtables.[object_id] = indexstats.[object_id]
INNER JOIN sys.schemas dbschemas on dbtables.[schema_id] = dbschemas.[schema_id]
INNER JOIN sys.indexes AS dbindexes ON dbindexes.[object_id] = indexstats.[object_id]
AND indexstats.index_id = dbindexes.index_id
WHERE indexstats.database_id = DB_ID()
ORDER BY indexstats.avg_fragmentation_in_percent desc
Rebuild regular indexes
Note: The regular indexes will get fragmented too. That should always be addressed with for example regular scheduled maintenance jobs in SQL Server. Consider having a 80%-90% fill factor to reduce further fragmentation and ensure the indexes are in good shape. You can also easily rebuild all the indexes on demand with the following SQL statement.
DECLARE @TableName varchar(255)
DECLARE TableCursor CURSOR FOR
SELECT table_name FROM information_schema.tables WHERE table_type = 'base table'
OPEN TableCursor
FETCH NEXT FROM TableCursor INTO @TableName
WHILE @@FETCH_STATUS = 0
BEGIN
DBCC DBREINDEX(@TableName,' ',80)
FETCH NEXT FROM TableCursor INTO @TableName
END
CLOSE TableCursor
DEALLOCATE TableCursor
Rebuild/defragment the table data
Unfortunately there is no way to defragment the heap without a clustered index. The screenshot below is from one of my master databases. As you see, it’s very fragmented.
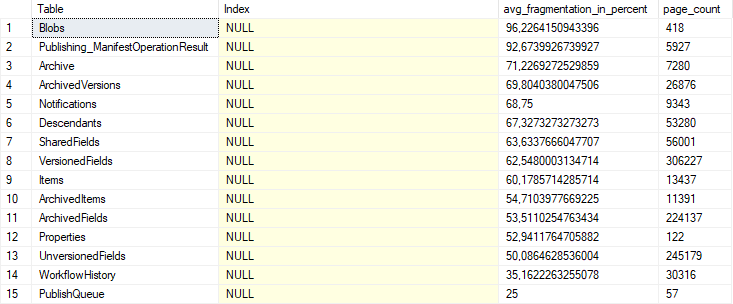
You can read more about Clustered and Non clustered indexes here:
https://stackoverflow.com/questions/1251636/what-do-clustered-and-non-clustered-index-actually-mean/1251652
We can replace some of the non-clustered indexes with clustered indexes, to make the heap organized. The SQL statements below can be applied to the core, master and web databases, but check how fragmented your tables are first. If it’s not too fragmented, this may even have a negative effect since data writes may reorganize the table data. Also notice the fill factors. I’ve used 80% or 90%, but the optimal values depends on how data written in your solution.
You can use he SQL Server commands below to replace existing non-clustered indexes with a corresponding clustered index.
DROP INDEX [ndxID] ON [Items]
CREATE UNIQUE CLUSTERED INDEX [ndxID] ON [Items] ([ID] ASC) WITH (FILLFACTOR = 80)
DROP INDEX [ndxUnique] ON [SharedFields]
CREATE UNIQUE CLUSTERED INDEX [ndxUnique] ON [SharedFields] ([ItemId] ASC, [FieldId] ASC) WITH (FILLFACTOR = 80)
DROP INDEX [ndxUnique] ON [UnversionedFields]
CREATE UNIQUE CLUSTERED INDEX [ndxUnique] ON [UnversionedFields] ([ItemId] ASC, [Language] ASC, [FieldId] ASC) WITH (FILLFACTOR = 80)
DROP INDEX [ndxUnique] ON [VersionedFields]
CREATE UNIQUE CLUSTERED INDEX [ndxUnique] ON [VersionedFields] ([ItemId] ASC, [Language] ASC, [Version] ASC, [FieldId] ASC) WITH (FILLFACTOR = 80)
DROP INDEX [ndxBlobId] ON [Blobs]
CREATE CLUSTERED INDEX [ndxBlobId] ON [Blobs] ([BlobId] ASC) WITH (FILLFACTOR = 80)
ALTER TABLE [Descendants] DROP CONSTRAINT [Descendants_PK]
ALTER TABLE [Descendants] ADD CONSTRAINT [Descendants_PK] PRIMARY KEY CLUSTERED ([Ancestor] ASC, [Descendant] ASC) WITH (FILLFACTOR = 80) ON [PRIMARY]
DROP INDEX [ndxID] ON [Links]
CREATE UNIQUE CLUSTERED INDEX [ndxID] ON [Links] ([ID] ASC) WITH (FILLFACTOR = 80)
ALTER TABLE [Notifications] DROP CONSTRAINT [PK_Notifications]
ALTER TABLE [Notifications] ADD CONSTRAINT [PK_Notifications] PRIMARY KEY CLUSTERED ([Id] ASC) WITH (FILLFACTOR = 80) ON [PRIMARY]
DROP INDEX [ndxCreated] ON [History]
CREATE CLUSTERED INDEX [ndxCreated] ON [History] ([Created] ASC) WITH (FILLFACTOR = 80)
DROP INDEX [ndxID] ON [WorkflowHistory]
CREATE UNIQUE CLUSTERED INDEX [ndxID] ON [WorkflowHistory] ([ID] ASC) WITH (FILLFACTOR = 90)
DROP INDEX [ndxID] ON [Properties]
CREATE UNIQUE CLUSTERED INDEX [ndxID] ON [Properties] ([ID] ASC) WITH (FILLFACTOR = 80)
You may also see other very fragmented tables, such as the Archive*-tables. Those are however used quite rarely, so I don’t really see any point in having a clustered index on those.
As far as I understand Sitecore support, this should be a supported action to perform. But again, don’t do it unless you gain something from it. Some say a larger prefetch cache may be more beneficial, however that hasn’t helped me much.
Hi Mikail & thanks for this interesting post. Can you explain what advantages – e.g. query performance increase or alike – can be expected from adding clustered indexes? And probably any „side effects“ like more disk space for storing the indexes on the drive, probably with some numbers you observed?
Thanks,
Oliver
Hi Mikael,
I’m a SQL Server DBA new to Sitecore and looking at a couple of Sitecore implementations that are suffering from performance problems and am quite surprised to see the Heap index strategy used by Sitecore. The heaps are very fragmented (>90%). Earlier today I had proposed that adding clustered indexes is the direction to move to help with performance and am wondering how your changes look over time. Have the performance improvements you gained from adding clustered indexes been maintained over time? Has the fragmentation rate for the indexes decreased after adding the clustered indexes?
Thanks,
Ron
I’ve had this in production for about a month now and I’m quite happy with the result. The heap stays a lot cleaner and queries on the CD servers are a bit faster. It’s mostly notable on large tables where the number of IOPS becomes lower. I run this on regular IaaS instances on Amazon AWS, where max disk IOPS is set per EBS volume.
However, some operations are also slower. For example updating the links table is sometimes slower, but for us it’s more valuable to ensure fast reading in that table than updating it fast.
As long as most operations are db reads and updates of existing rows, the change is beneficial. But when there are a lot of inserts/deletes, this is not so good.
What did you use as your clustered index key for the Items table? I have read that using a GUID is not a good choice.